--
參考資源
- [Python]如何Speech to Text: SpeechRecognition - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天 (ithome.com.tw)
- python使用Speech_Recognition实现普通话识别(一)_kimicren的博客-CSDN博客
- Whisper UI,開源免費AI語音轉文字軟體,一鍵產生逐字稿與字幕檔 | Ivon的部落格 (ivonblog.com)
- OpenAI Whisper Audio Transcription Benchmarked on 18 GPUs: Up to 3,000 WPM | Tom's Hardware (tomshardware.com)
一開始測試 SpeechRecognition,後來看到 OpenAI 的 Whisper,可以使用 CPU 不過速度很慢,一個英文單字也需要 10 秒的執行時間,根據網路資料使用 Nvidia 顯示卡 CUDA 可以節省時間,Hoyo 沒顯示卡所以無法證實
--
Whisper 安裝
Whisper 需要 Python 3.9.9 以上版本,安裝完成後使用 pip 安裝
|
1 |
pip install -U openai-whisper |
考慮到音頻檔案格式轉換,因此還需要安裝 ffmpeg
--
使用
|
1 |
whisper apple.mp3 |
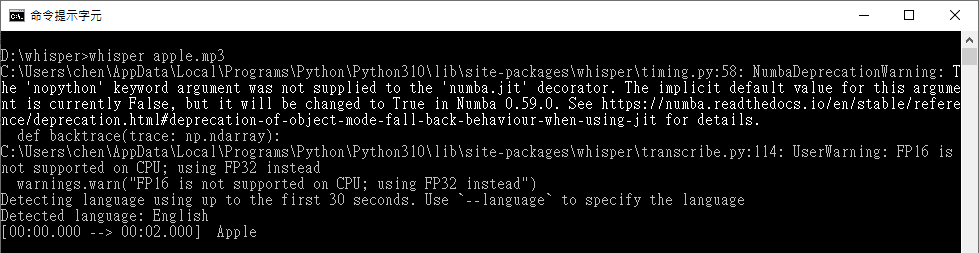
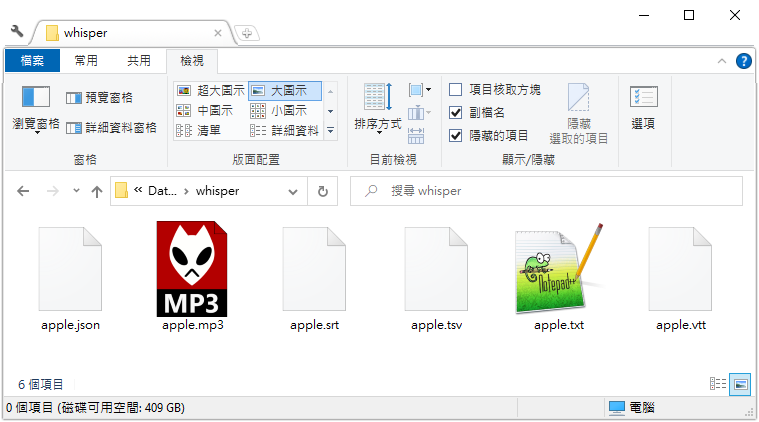
指令完成預設會輸出所有格式檔案:json, srt, tsv, txt, vtt
指定模型,初次使用會自動下載
|
1 2 3 4 |
whisper OSR_us_000_0061_8k.wav --model medium C:\Users\chen\AppData\Local\Programs\Python\Python310\lib\site-packages\whisper\timing.py:58: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details. def backtrace(trace: np.ndarray): 11%|████▎ | 167M/1.42G [01:12<08:20, 2.70MiB/s] |
指定英文最小模型快速辨識
|
1 |
whisper apple.mp3 --model tiny.en --language English --fp16 False --output_format txt |
--
Apache 網頁執行
要從 Apache 網頁呼叫執行,需要注意的都是路徑問題,沒有使用者權限問題。模型要複製到另外的目錄
|
1 |
/usr/local/bin/whisper /tmp/audio.webm --model tiny.en --language English --fp16 False --output_format txt --output_dir /tmp --model_dir /data/model |
--
參數
- --model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large-v1,large-v2,large}
name of the Whisper model to use (default: small)
.en 是英文專屬模型 - --model_dir MODEL_DIR
the path to save model files; uses ~/.cache/whisper by default (default: None)
模型路徑 - --language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,he,hi,hr,ht,hu,hy,id,is,it,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,zh,Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,Bulgarian,Burmese,Castilian,Catalan,Chinese,Croatian,Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,French,Galician,Georgian,German,Greek,Gujarati,Haitian,Haitian Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,Vietnamese,Welsh,Yiddish,Yoruba}
為設定時,執行時會自動偵測 - --output_format {txt,vtt,srt,tsv,json,all}, -f {txt,vtt,srt,tsv,json,all}
format of the output file; if not specified, all available formats will be produced (default:all)
檔案輸出格式,和畫面輸出無關 - --threads THREADS number of threads used by torch for CPU inference; supercedes MKL_NUM_THREADS/OMP_NUM_THREADS
(default: 0)
使用 CPU 時,指定使用核心數
--
不出現警告
|
1 |
PYTHONWARNINGS=ignore whisper /data1/tmp/audio.webm --model small --language Chinese --output_format txt --fp16 False |
--
硬體規格建議
🧠 不同模型大小與延遲估算(以 30 秒音訊為例)
| 模型 | 平均處理時間(CPU) | GPU (如 RTX 3060+) 處理時間 | 秒回建議 |
|---|---|---|---|
tiny |
4–6 秒 | < 1 秒 | ✅ 可秒回 |
base |
8–12 秒 | ~1 秒 | ✅ 可秒回 |
small |
15–20 秒 | ~2–3 秒 | ⚠️ 近即時 |
medium |
30–50 秒 | ~5–7 秒 | ❌ 不適合秒回 |
large |
1–2 分鐘以上 | ~10 秒以上 | ❌ 不適合秒回 |
✅ GPU 加速(強烈建議)
| 元件 | 推薦規格 |
|---|---|
| GPU | NVIDIA RTX 3060 / 4060 以上(CUDA 支援) |
| CUDA 驅動 | CUDA Toolkit 11.x + cuDNN |
| RAM | 16 GB 以上 |
| CPU | Intel i5/Ryzen 5(或更好) |
| SSD | 快速 NVMe SSD |
✅ 整體結論
| 用途 | 建議選擇 |
|---|---|
| 打遊戲(1080p) | RTX 4060(效能更好、功耗更低) |
| 打遊戲(2K 或有高材質MOD) | RTX 3060 12GB(顯存夠用) |
| AI、Stable Diffusion、創作用途 | RTX 3060 12GB(顯存重要) |
| 希望長時間使用、節能省電 | RTX 4060(新架構更省電) |
📊 效能比較
| 項目 | RTX 3060 12GB | RTX 4060 8GB |
|---|---|---|
| CUDA 核心 | 3584 | 3072 |
| 顯存 | 12GB GDDR6 | 8GB GDDR6(但頻寬小) |
| 記憶體介面 | 192-bit | 128-bit(較小) |
| 功耗 | 約 170W | 115W(節能) |
| 架構 | Ampere(舊) | Ada Lovelace(新) |
| 光追效能 | 較差 | 較好(第三代 RT 核心) |
| DLSS | 有(DLSS 2) | 有(DLSS 3) |
| 效能(大多數遊戲) | 稍低 | 略高(5~15%) |
--
CUDA
--
11,299 total views, 4 views today